> ## Documentation Index
> Fetch the complete documentation index at: https://private-7c7dfe99-mintlify-fbfa8bee.mintlify.site/llms.txt
> Use this file to discover all available pages before exploring further.
# Managed
> Déploiement de Managed ClickStack
export const TrackedLink = ({href, eventName, children, ...rest}) => {
const handleClick = () => {
try {
if (typeof window !== "undefined" && window.galaxy && eventName) {
window.galaxy.track(eventName, {
interaction: "click"
});
}
} catch (e) {}
};
return
{children}
;
};
export const Image = ({img, alt, size}) => {
return
 ;
};
Ce **guide s’adresse aux utilisateurs existants de ClickHouse Cloud**. Si vous découvrez ClickHouse Cloud, nous vous recommandons notre guide de [prise en main](/fr/clickstack/getting-started/managed) pour Managed ClickStack.
Dans ce modèle de déploiement, ClickHouse et l’interface utilisateur de ClickStack (HyperDX) sont tous deux hébergés dans ClickHouse Cloud, ce qui réduit au minimum le nombre de composants que l’utilisateur doit auto-héberger.
En plus d’alléger la gestion de l’infrastructure, ce modèle de déploiement garantit que l’authentification est intégrée au SSO/SAML de ClickHouse Cloud. Contrairement aux déploiements auto-hébergés, il n’est pas non plus nécessaire de provisionner une instance MongoDB pour stocker l’état de l’application — comme les tableaux de bord, les recherches enregistrées, les paramètres utilisateur et les alertes. Les utilisateurs bénéficient également de :
* La mise à l’échelle automatique des ressources de calcul, indépendamment du stockage
* Une rétention à faible coût et pratiquement illimitée grâce au stockage objet
* La possibilité d’isoler indépendamment les charges de travail de lecture et d’écriture avec les Warehouses.
* Une authentification intégrée
* Des sauvegardes automatisées
* Des fonctionnalités de sécurité et de conformité
* Des mises à niveau transparentes
Dans ce mode, l’ingestion des données est entièrement à la charge de l’utilisateur. Vous pouvez ingérer des données dans Managed ClickStack à l’aide de votre propre OpenTelemetry Collector hébergé, par ingestion directe depuis des bibliothèques clientes, des moteurs de table natifs de ClickHouse (tels que Kafka ou S3), des pipelines ETL ou ClickPipes — le service d’ingestion géré de ClickHouse Cloud. Cette approche offre le moyen le plus simple et le plus performant d’exploiter ClickStack.
;
};
Ce **guide s’adresse aux utilisateurs existants de ClickHouse Cloud**. Si vous découvrez ClickHouse Cloud, nous vous recommandons notre guide de [prise en main](/fr/clickstack/getting-started/managed) pour Managed ClickStack.
Dans ce modèle de déploiement, ClickHouse et l’interface utilisateur de ClickStack (HyperDX) sont tous deux hébergés dans ClickHouse Cloud, ce qui réduit au minimum le nombre de composants que l’utilisateur doit auto-héberger.
En plus d’alléger la gestion de l’infrastructure, ce modèle de déploiement garantit que l’authentification est intégrée au SSO/SAML de ClickHouse Cloud. Contrairement aux déploiements auto-hébergés, il n’est pas non plus nécessaire de provisionner une instance MongoDB pour stocker l’état de l’application — comme les tableaux de bord, les recherches enregistrées, les paramètres utilisateur et les alertes. Les utilisateurs bénéficient également de :
* La mise à l’échelle automatique des ressources de calcul, indépendamment du stockage
* Une rétention à faible coût et pratiquement illimitée grâce au stockage objet
* La possibilité d’isoler indépendamment les charges de travail de lecture et d’écriture avec les Warehouses.
* Une authentification intégrée
* Des sauvegardes automatisées
* Des fonctionnalités de sécurité et de conformité
* Des mises à niveau transparentes
Dans ce mode, l’ingestion des données est entièrement à la charge de l’utilisateur. Vous pouvez ingérer des données dans Managed ClickStack à l’aide de votre propre OpenTelemetry Collector hébergé, par ingestion directe depuis des bibliothèques clientes, des moteurs de table natifs de ClickHouse (tels que Kafka ou S3), des pipelines ETL ou ClickPipes — le service d’ingestion géré de ClickHouse Cloud. Cette approche offre le moyen le plus simple et le plus performant d’exploiter ClickStack.
### Convient à
Ce modèle de déploiement est idéal dans les scénarios suivants :
1. Vous disposez déjà de données d'observabilité dans ClickHouse Cloud et souhaitez les visualiser avec ClickStack.
2. Vous exploitez déjà un déploiement d'observabilité à grande échelle et avez besoin des performances et de la scalabilité dédiées de ClickStack sur ClickHouse Cloud.
3. Vous utilisez déjà ClickHouse Cloud pour l'analytique et souhaitez instrumenter votre application à l'aide des bibliothèques d'instrumentation de ClickStack, en envoyant les données vers le même cluster. Dans ce cas, nous recommandons d'utiliser les [warehouses](/fr/products/cloud/features/infrastructure/warehouses) afin d'isoler les ressources de calcul des charges de travail d'observabilité.
## Étapes de configuration
Ce guide suppose que vous avez déjà créé un service ClickHouse Cloud. Si ce n'est pas encore fait, suivez le guide [Prise en main](/fr/clickstack/getting-started/managed) pour Managed ClickStack. Vous obtiendrez ainsi un service dans le même état que celui décrit dans ce guide, c'est-à-dire prêt à recevoir des données d'observabilité avec ClickStack activé.
### Créer un nouveau service
Sur la page d’accueil de ClickHouse Cloud, sélectionnez `New service` pour créer un nouveau service.
### Indiquez votre fournisseur, votre région et votre ressource
**Scale vs Enterprise**
Nous recommandons ce [niveau Scale](/fr/products/cloud/features/cloud-tiers) pour la plupart des charges de travail ClickStack. Choisissez le niveau Enterprise si vous avez besoin de fonctionnalités de sécurité avancées comme SAML, CMEK ou la conformité HIPAA. Il propose également des profils matériels personnalisés pour les déploiements ClickStack de très grande envergure. Dans ce cas, nous vous recommandons de contacter le support.
Sélectionnez le fournisseur Cloud et la région.
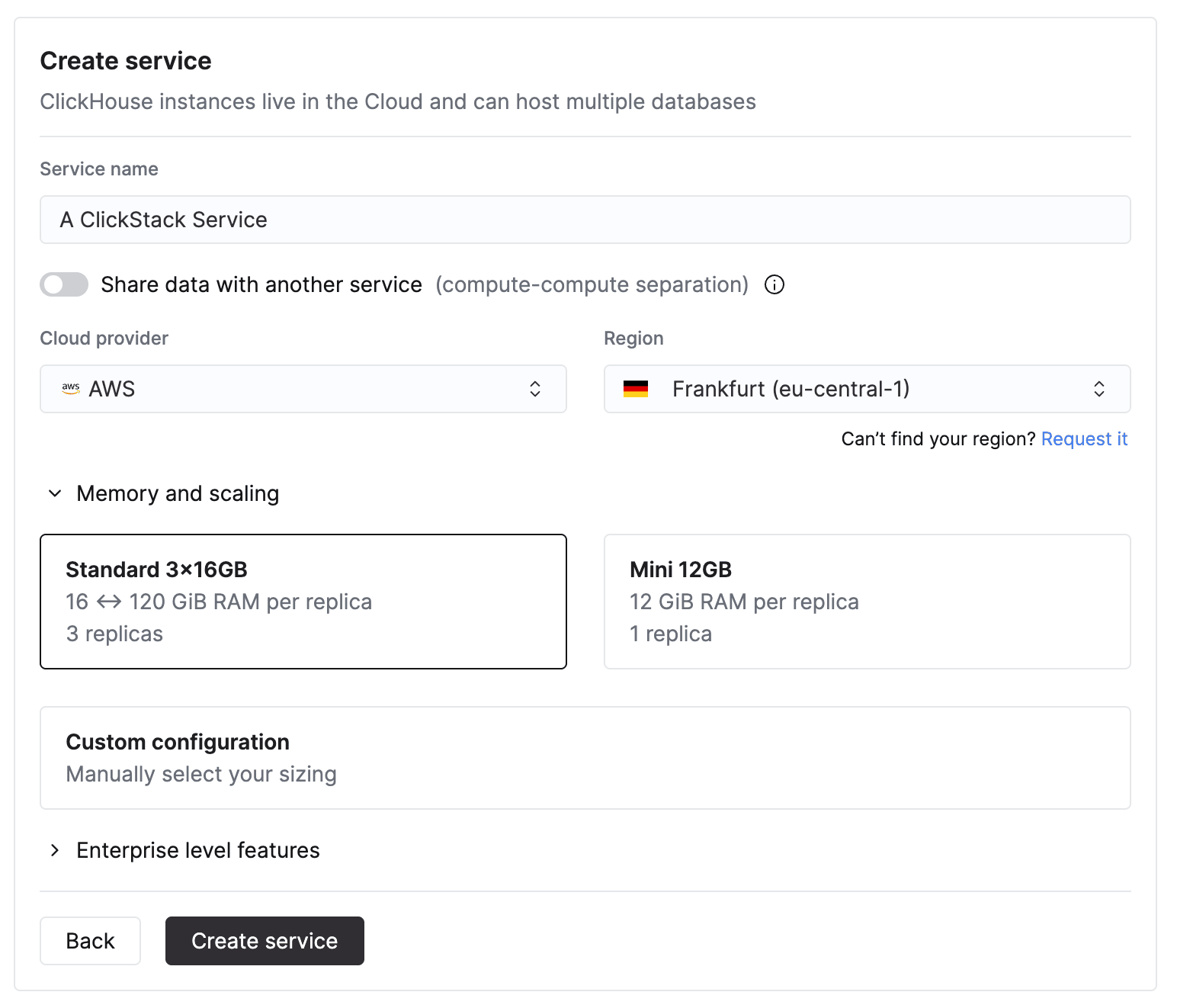 Lorsque vous indiquez les CPU et la mémoire, estimez-les en fonction de votre débit d’ingestion ClickStack attendu. Le tableau ci-dessous fournit des repères pour dimensionner ces ressources.
| Volume d’ingestion mensuel | Capacité de calcul recommandée |
| -------------------------- | ------------------------------ |
| \< 10 TB / mois | 2 vCPU × 3 répliques |
| 10–50 TB / mois | 4 vCPU × 3 répliques |
| 50–100 TB / mois | 8 vCPU × 3 répliques |
| 100–500 TB / mois | 30 vCPU × 3 répliques |
| 1 PB+ / mois | 59 vCPU × 3 répliques |
Ces recommandations reposent sur les hypothèses suivantes :
* Le volume de données correspond au **volume d’ingestion non compressé** par mois et s’applique aussi bien aux logs qu’aux traces.
* Les modèles de requêtes sont typiques des cas d’usage d’observabilité, la plupart des requêtes portant sur des **données récentes**, généralement des 24 dernières heures.
* L’ingestion est relativement **uniforme sur l’ensemble du mois**. Si vous prévoyez un trafic irrégulier ou des pics, vous devez prévoir une marge de capacité supplémentaire.
* Le stockage est géré séparément via le stockage objet ClickHouse Cloud et ne constitue pas un facteur limitant pour la rétention. Nous partons du principe que les données conservées plus longtemps sont rarement consultées.
Des ressources de calcul supplémentaires peuvent être nécessaires pour des modes d’accès qui interrogent régulièrement des intervalles de temps plus longs, effectuent des agrégations lourdes ou prennent en charge un grand nombre d’utilisateurs simultanés.
Bien que deux répliques puissent répondre aux exigences de CPU et de mémoire pour un débit d’ingestion donné, nous recommandons d’utiliser trois répliques lorsque cela est possible afin d’obtenir la même capacité totale et d’améliorer la redondance du service.
Ces valeurs sont **uniquement des estimations** et doivent être utilisées comme point de départ. Les besoins réels dépendent de la complexité des requêtes, de la concurrence, des politiques de rétention et de la variabilité du débit d’ingestion. Surveillez toujours l’utilisation des ressources et adaptez le dimensionnement si nécessaire.
Une fois vos besoins définis, le provisionnement de votre service Managed ClickStack prendra რამდენიმე minutes. N’hésitez pas à explorer le reste de la [console ClickHouse Cloud](/fr/products/cloud/getting-started/intro) pendant le provisionnement.
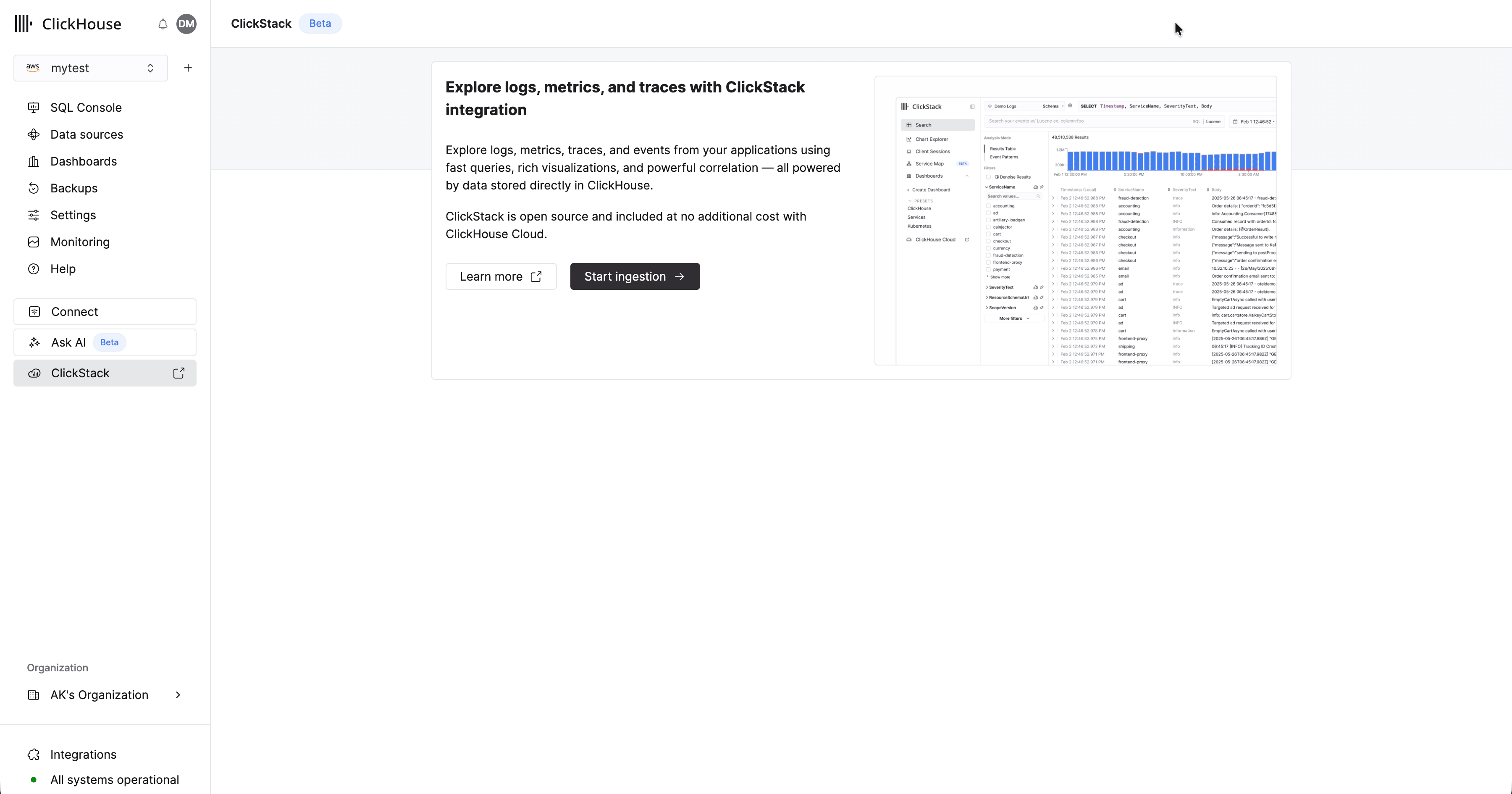
Une fois **le provisionnement terminé, l’option 'ClickStack' dans le menu de gauche sera activée**.
### Configurer l’ingestion
Une fois votre service provisionné, assurez-vous que ce service est sélectionné, puis cliquez sur "ClickStack" dans le menu de gauche.
Lorsque vous indiquez les CPU et la mémoire, estimez-les en fonction de votre débit d’ingestion ClickStack attendu. Le tableau ci-dessous fournit des repères pour dimensionner ces ressources.
| Volume d’ingestion mensuel | Capacité de calcul recommandée |
| -------------------------- | ------------------------------ |
| \< 10 TB / mois | 2 vCPU × 3 répliques |
| 10–50 TB / mois | 4 vCPU × 3 répliques |
| 50–100 TB / mois | 8 vCPU × 3 répliques |
| 100–500 TB / mois | 30 vCPU × 3 répliques |
| 1 PB+ / mois | 59 vCPU × 3 répliques |
Ces recommandations reposent sur les hypothèses suivantes :
* Le volume de données correspond au **volume d’ingestion non compressé** par mois et s’applique aussi bien aux logs qu’aux traces.
* Les modèles de requêtes sont typiques des cas d’usage d’observabilité, la plupart des requêtes portant sur des **données récentes**, généralement des 24 dernières heures.
* L’ingestion est relativement **uniforme sur l’ensemble du mois**. Si vous prévoyez un trafic irrégulier ou des pics, vous devez prévoir une marge de capacité supplémentaire.
* Le stockage est géré séparément via le stockage objet ClickHouse Cloud et ne constitue pas un facteur limitant pour la rétention. Nous partons du principe que les données conservées plus longtemps sont rarement consultées.
Des ressources de calcul supplémentaires peuvent être nécessaires pour des modes d’accès qui interrogent régulièrement des intervalles de temps plus longs, effectuent des agrégations lourdes ou prennent en charge un grand nombre d’utilisateurs simultanés.
Bien que deux répliques puissent répondre aux exigences de CPU et de mémoire pour un débit d’ingestion donné, nous recommandons d’utiliser trois répliques lorsque cela est possible afin d’obtenir la même capacité totale et d’améliorer la redondance du service.
Ces valeurs sont **uniquement des estimations** et doivent être utilisées comme point de départ. Les besoins réels dépendent de la complexité des requêtes, de la concurrence, des politiques de rétention et de la variabilité du débit d’ingestion. Surveillez toujours l’utilisation des ressources et adaptez le dimensionnement si nécessaire.
Une fois vos besoins définis, le provisionnement de votre service Managed ClickStack prendra რამდენიმე minutes. N’hésitez pas à explorer le reste de la [console ClickHouse Cloud](/fr/products/cloud/getting-started/intro) pendant le provisionnement.
Une fois **le provisionnement terminé, l’option 'ClickStack' dans le menu de gauche sera activée**.
### Configurer l’ingestion
Une fois votre service provisionné, assurez-vous que ce service est sélectionné, puis cliquez sur "ClickStack" dans le menu de gauche.
 Sélectionnez "Start Ingestion" et vous serez invité à choisir une source d’ingestion. Managed ClickStack prend en charge OpenTelemetry et [Vector](https://vector.dev/) comme principales sources d’ingestion. Les utilisateurs peuvent toutefois aussi envoyer des données directement vers ClickHouse selon leur propre schéma, à l’aide de l’une des [intégrations prises en charge par ClickHouse Cloud](/fr/integrations/home).
Sélectionnez "Start Ingestion" et vous serez invité à choisir une source d’ingestion. Managed ClickStack prend en charge OpenTelemetry et [Vector](https://vector.dev/) comme principales sources d’ingestion. Les utilisateurs peuvent toutefois aussi envoyer des données directement vers ClickHouse selon leur propre schéma, à l’aide de l’une des [intégrations prises en charge par ClickHouse Cloud](/fr/integrations/home).
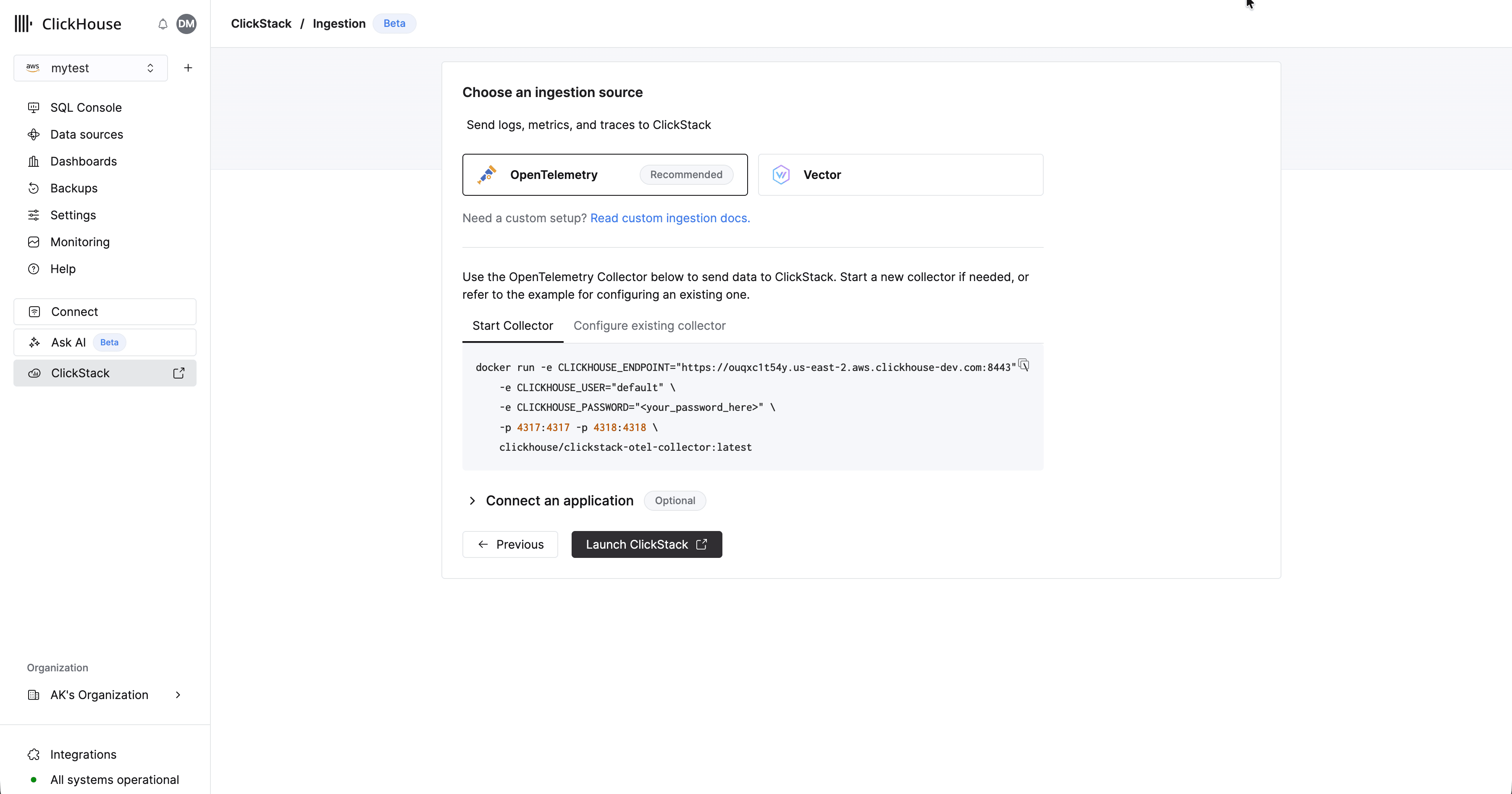 **OpenTelemetry recommandé**
L’utilisation d’OpenTelemetry est fortement recommandée pour l’ingestion.
Il offre l’expérience la plus simple et la plus optimisée, avec des schémas prêts à l’emploi spécialement conçus pour fonctionner efficacement avec ClickStack.
Pour envoyer des données OpenTelemetry à Managed ClickStack, il est recommandé d’utiliser un OpenTelemetry Collector. Le collector agit comme une passerelle : il reçoit les données OpenTelemetry de vos applications (et d’autres collectors) et les transmet à ClickHouse Cloud.
Si vous n’avez pas déjà un collector en cours d’exécution, démarrez-en un en suivant les étapes ci-dessous. Si vous disposez déjà de collectors, un exemple de configuration est également fourni.
### Démarrer un collector
La suite de cette procédure part du principe que vous utilisez l’option recommandée, à savoir la **distribution ClickStack de l’OpenTelemetry Collector**, qui inclut des traitements supplémentaires et est spécifiquement optimisée pour ClickHouse Cloud. Si vous souhaitez utiliser votre propre OpenTelemetry Collector, consultez [« Configurer des collectors existants »](#configure-existing-collectors)
Pour démarrer rapidement, copiez et exécutez la commande Docker affichée.
**OpenTelemetry recommandé**
L’utilisation d’OpenTelemetry est fortement recommandée pour l’ingestion.
Il offre l’expérience la plus simple et la plus optimisée, avec des schémas prêts à l’emploi spécialement conçus pour fonctionner efficacement avec ClickStack.
Pour envoyer des données OpenTelemetry à Managed ClickStack, il est recommandé d’utiliser un OpenTelemetry Collector. Le collector agit comme une passerelle : il reçoit les données OpenTelemetry de vos applications (et d’autres collectors) et les transmet à ClickHouse Cloud.
Si vous n’avez pas déjà un collector en cours d’exécution, démarrez-en un en suivant les étapes ci-dessous. Si vous disposez déjà de collectors, un exemple de configuration est également fourni.
### Démarrer un collector
La suite de cette procédure part du principe que vous utilisez l’option recommandée, à savoir la **distribution ClickStack de l’OpenTelemetry Collector**, qui inclut des traitements supplémentaires et est spécifiquement optimisée pour ClickHouse Cloud. Si vous souhaitez utiliser votre propre OpenTelemetry Collector, consultez [« Configurer des collectors existants »](#configure-existing-collectors)
Pour démarrer rapidement, copiez et exécutez la commande Docker affichée.
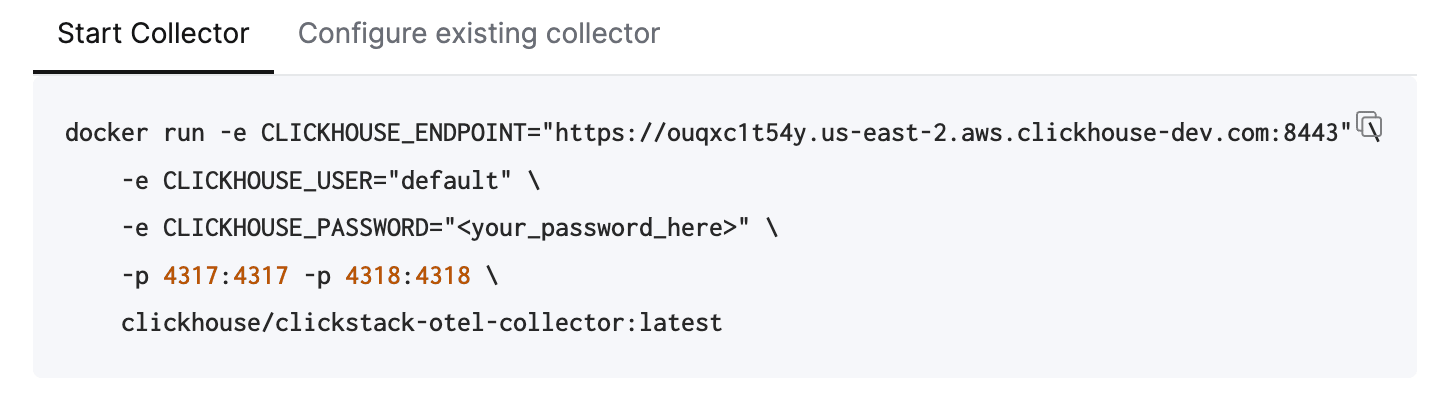 Cette commande doit déjà contenir vos identifiants de connexion préremplis.
**Déploiement en production**
Bien que cette commande utilise l’utilisateur `default` pour se connecter à Managed ClickStack, vous devriez créer un utilisateur dédié lors du [passage en production](/fr/clickstack/managing/production#create-a-database-ingestion-user-managed) et modifier votre configuration.
L’exécution de cette seule commande démarre le ClickStack collector avec des endpoints OTLP exposés sur les ports 4317 (gRPC) et 4318 (HTTP). Si vous disposez déjà d’une instrumentation OpenTelemetry et d’agents, vous pouvez immédiatement commencer à envoyer des données de télémétrie vers ces endpoints.
### Configurer des collectors existants
Vous pouvez également configurer vos propres OpenTelemetry Collectors existants ou utiliser votre propre distribution du collector.
**ClickHouse exporter requis**
Si vous utilisez votre propre distribution, par exemple l’[image contrib](https://github.com/open-telemetry/opentelemetry-collector-contrib), assurez-vous qu’elle inclut le [ClickHouse exporter](https://github.com/open-telemetry/opentelemetry-collector-contrib/tree/main/exporter/clickhouseexporter).
À cette fin, un exemple de configuration d’OpenTelemetry Collector vous est fourni. Il utilise le ClickHouse exporter avec les paramètres appropriés et expose des receivers OTLP. Cette configuration correspond aux interfaces et au comportement attendus par la distribution ClickStack.
Pour plus de détails sur la configuration des collectors OpenTelemetry, consultez [« Ingestion avec OpenTelemetry »](/fr/clickstack/ingesting-data/opentelemetry)
### Démarrer l’ingestion (facultatif)
Si vous avez des applications ou une infrastructure existantes à instrumenter avec OpenTelemetry, accédez aux guides correspondants depuis l’UI.
Pour instrumenter vos applications afin de collecter des traces et des logs, utilisez les [SDKs de langages pris en charge](/fr/clickstack/ingesting-data/sdks/index), qui envoient les données à votre OpenTelemetry Collector, lequel agit comme une passerelle pour l’ingestion dans Managed ClickStack.
Les logs peuvent être [collectés à l’aide d’OpenTelemetry Collectors](/fr/clickstack/integration-examples/host-logs) exécutés en mode agent, qui transmettent les données au même collector. Pour le monitoring Kubernetes, suivez le [guide dédié](/fr/clickstack/integration-examples/kubernetes). Pour les autres intégrations, consultez nos [guides de démarrage rapide](/fr/clickstack/integration-examples/index).
### Données de démonstration
Sinon, si vous n’avez pas de données existantes, essayez l’un de nos jeux de données d’exemple.
* [Jeu de données d’exemple](/fr/clickstack/example-datasets/sample-data) - Chargez un jeu de données d’exemple depuis notre démo publique. Diagnostiquez un problème simple.
* [Fichiers locaux et métriques](/fr/clickstack/example-datasets/local-data) - Chargez des fichiers locaux et surveillez le système sur OSX ou Linux à l’aide d’un collector OTel local.
Cette commande doit déjà contenir vos identifiants de connexion préremplis.
**Déploiement en production**
Bien que cette commande utilise l’utilisateur `default` pour se connecter à Managed ClickStack, vous devriez créer un utilisateur dédié lors du [passage en production](/fr/clickstack/managing/production#create-a-database-ingestion-user-managed) et modifier votre configuration.
L’exécution de cette seule commande démarre le ClickStack collector avec des endpoints OTLP exposés sur les ports 4317 (gRPC) et 4318 (HTTP). Si vous disposez déjà d’une instrumentation OpenTelemetry et d’agents, vous pouvez immédiatement commencer à envoyer des données de télémétrie vers ces endpoints.
### Configurer des collectors existants
Vous pouvez également configurer vos propres OpenTelemetry Collectors existants ou utiliser votre propre distribution du collector.
**ClickHouse exporter requis**
Si vous utilisez votre propre distribution, par exemple l’[image contrib](https://github.com/open-telemetry/opentelemetry-collector-contrib), assurez-vous qu’elle inclut le [ClickHouse exporter](https://github.com/open-telemetry/opentelemetry-collector-contrib/tree/main/exporter/clickhouseexporter).
À cette fin, un exemple de configuration d’OpenTelemetry Collector vous est fourni. Il utilise le ClickHouse exporter avec les paramètres appropriés et expose des receivers OTLP. Cette configuration correspond aux interfaces et au comportement attendus par la distribution ClickStack.
Pour plus de détails sur la configuration des collectors OpenTelemetry, consultez [« Ingestion avec OpenTelemetry »](/fr/clickstack/ingesting-data/opentelemetry)
### Démarrer l’ingestion (facultatif)
Si vous avez des applications ou une infrastructure existantes à instrumenter avec OpenTelemetry, accédez aux guides correspondants depuis l’UI.
Pour instrumenter vos applications afin de collecter des traces et des logs, utilisez les [SDKs de langages pris en charge](/fr/clickstack/ingesting-data/sdks/index), qui envoient les données à votre OpenTelemetry Collector, lequel agit comme une passerelle pour l’ingestion dans Managed ClickStack.
Les logs peuvent être [collectés à l’aide d’OpenTelemetry Collectors](/fr/clickstack/integration-examples/host-logs) exécutés en mode agent, qui transmettent les données au même collector. Pour le monitoring Kubernetes, suivez le [guide dédié](/fr/clickstack/integration-examples/kubernetes). Pour les autres intégrations, consultez nos [guides de démarrage rapide](/fr/clickstack/integration-examples/index).
### Données de démonstration
Sinon, si vous n’avez pas de données existantes, essayez l’un de nos jeux de données d’exemple.
* [Jeu de données d’exemple](/fr/clickstack/example-datasets/sample-data) - Chargez un jeu de données d’exemple depuis notre démo publique. Diagnostiquez un problème simple.
* [Fichiers locaux et métriques](/fr/clickstack/example-datasets/local-data) - Chargez des fichiers locaux et surveillez le système sur OSX ou Linux à l’aide d’un collector OTel local.
[Vector](https://vector.dev) est un pipeline de données d’observabilité haute performance, indépendant des fournisseurs, particulièrement apprécié pour l’ingestion de logs grâce à sa flexibilité et à sa faible empreinte en ressources.
Lorsque vous utilisez Vector avec ClickStack, vous devez définir vos propres schémas. Ces schémas peuvent suivre les conventions OpenTelemetry, mais ils peuvent aussi être entièrement personnalisés pour représenter des structures d’événements définies par l’utilisateur.
**Timestamp requis**
La seule exigence stricte pour Managed ClickStack est que les données incluent une **colonne timestamp** (ou un champ temporel équivalent), qui peut être déclarée lors de la configuration de la source de données dans l’UI ClickStack.
La suite suppose que vous disposez d’une instance de Vector en cours d’exécution, préconfigurée avec des pipelines d’ingestion, qui transmet des données.
### Créer une base de données et une table
Vector exige qu’une table et un schéma soient définis avant l’ingestion des données.
Créez d’abord une base de données. Vous pouvez le faire via la [ClickHouse Cloud console](/fr/products/cloud/features/sql-console-features/sql-console).
Par exemple, créez une base de données pour les logs :
```sql theme={null}
CREATE DATABASE IF NOT EXISTS logs
```
Créez ensuite une table dont le schéma correspond à la structure de vos données de logs. L’exemple ci-dessous suppose un format classique de logs d’accès Nginx :
```sql theme={null}
CREATE TABLE logs.nginx_logs
(
`time_local` DateTime,
`remote_addr` IPv4,
`remote_user` LowCardinality(String),
`request` String,
`status` UInt16,
`body_bytes_sent` UInt64,
`http_referer` String,
`http_user_agent` String,
`http_x_forwarded_for` LowCardinality(String),
`request_time` Float32,
`upstream_response_time` Float32,
`http_host` String
)
ENGINE = MergeTree
ORDER BY (toStartOfMinute(time_local), status, remote_addr);
```
Votre table doit correspondre au schéma de sortie généré par Vector. Ajustez le schéma en fonction de vos données, en suivant les [bonnes pratiques recommandées pour les schémas](/fr/concepts/best-practices/select-data-type).
Nous vous recommandons vivement de bien comprendre le fonctionnement des [clés primaires](/fr/concepts/core-concepts/primary-indexes) dans ClickHouse et de choisir une clé de tri en fonction de vos schémas d’accès. Consultez les recommandations [spécifiques à ClickStack](/fr/clickstack/managing/performance-tuning#choosing-a-primary-key) pour choisir une clé primaire.
Une fois la table créée, copiez l’extrait de configuration affiché. Ajustez l’entrée afin de consommer vos pipelines existants, ainsi que la table cible et la base de données si nécessaire. Les informations d’identification devraient être préremplies.
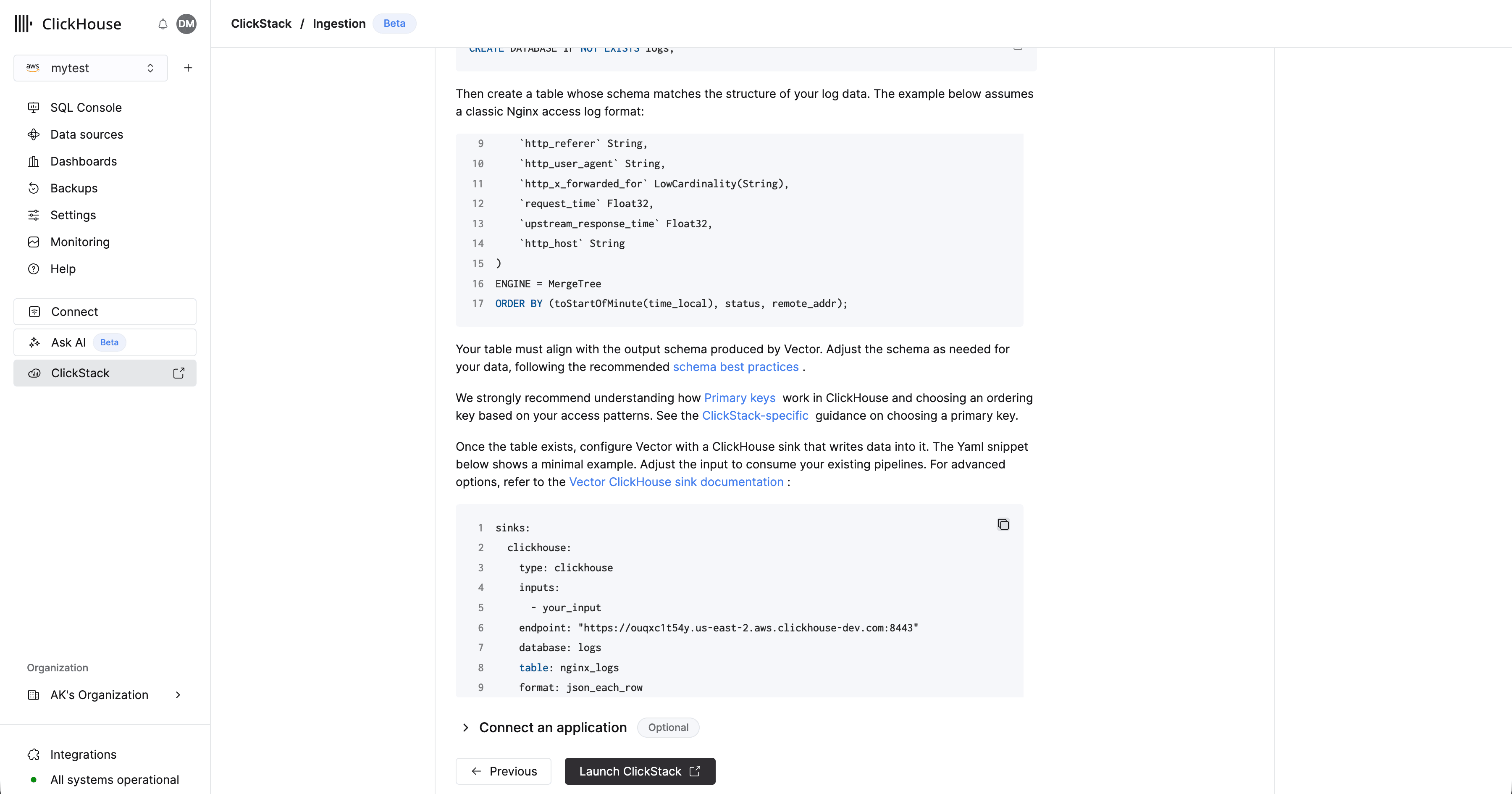 Pour plus d’exemples sur l’ingestion de données avec Vector, consultez ["Ingestion avec Vector"](/fr/clickstack/ingesting-data/vector) ou la [documentation du sink ClickHouse de Vector](https://vector.dev/docs/reference/configuration/sinks/clickhouse/) pour les options avancées.
Pour plus d’exemples sur l’ingestion de données avec Vector, consultez ["Ingestion avec Vector"](/fr/clickstack/ingesting-data/vector) ou la [documentation du sink ClickHouse de Vector](https://vector.dev/docs/reference/configuration/sinks/clickhouse/) pour les options avancées.
### Accéder à l’interface de ClickStack
Sélectionnez « Launch ClickStack » pour accéder à l’interface ClickStack (HyperDX). Vous serez automatiquement authentifié, puis redirigé.
Des sources de données seront automatiquement créées pour toutes les données OpenTelemetry.
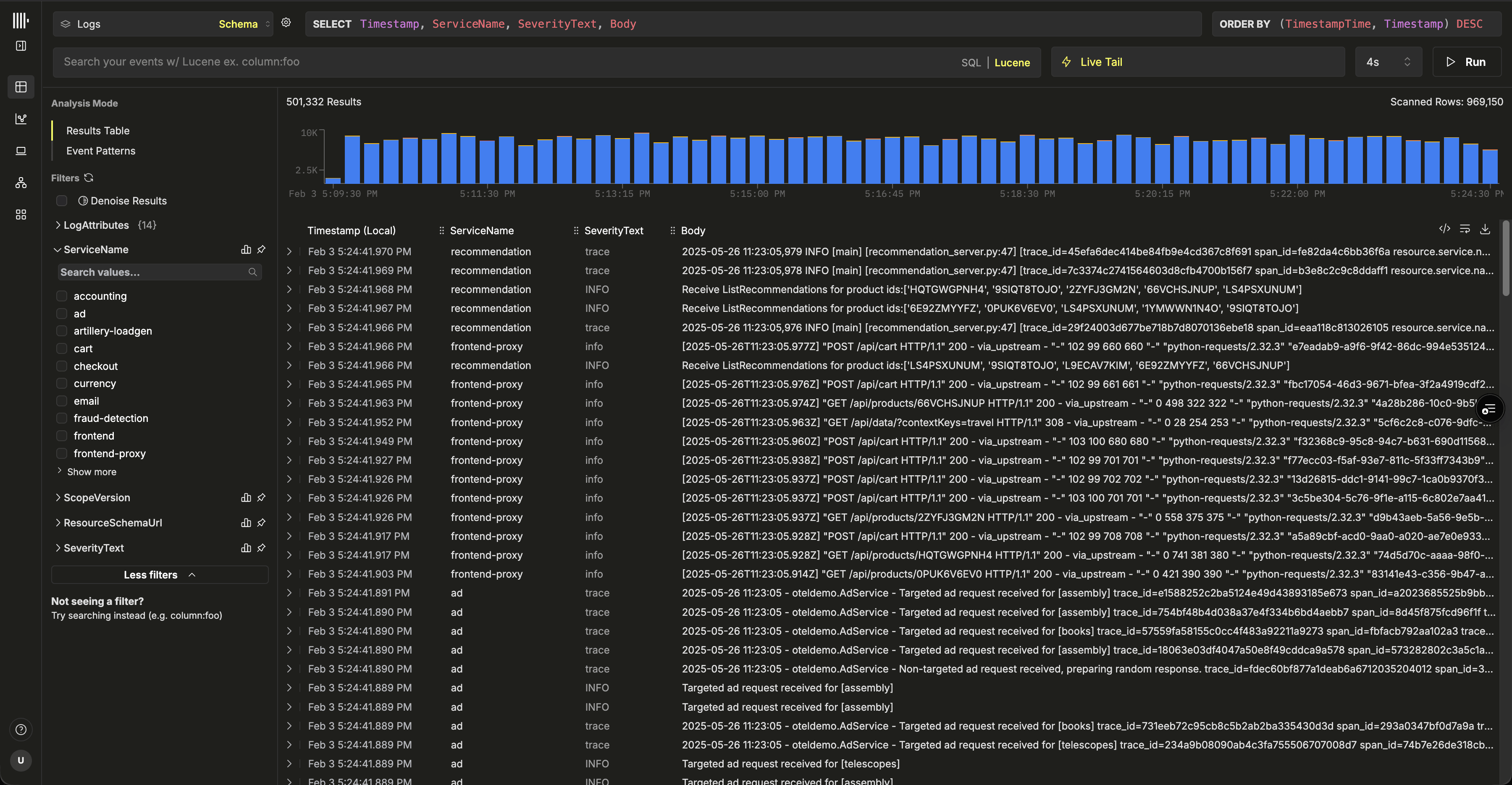 Si vous utilisez Vector, vous devrez créer vos propres sources de données. Il vous sera demandé d’en créer une lors de votre première connexion. Ci-dessous, nous montrons un exemple de configuration pour une source de données de logs.
Si vous utilisez Vector, vous devrez créer vos propres sources de données. Il vous sera demandé d’en créer une lors de votre première connexion. Ci-dessous, nous montrons un exemple de configuration pour une source de données de logs.
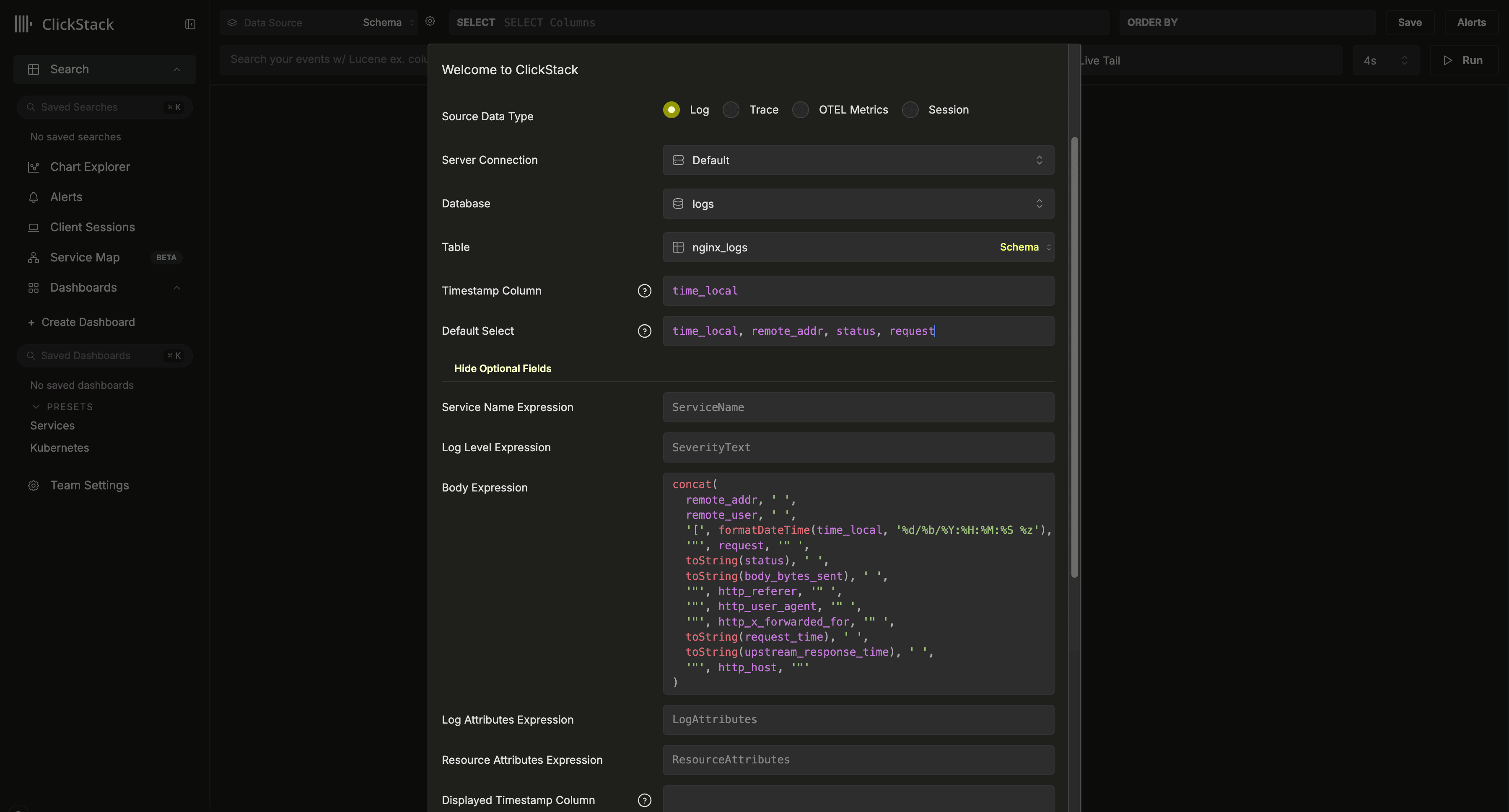 Cette configuration suppose un schéma de type Nginx avec une colonne `time_local` utilisée comme horodatage. Idéalement, il doit s’agir de la colonne d’horodatage déclarée dans la clé primaire. **Cette colonne est obligatoire**.
Nous vous recommandons également de mettre à jour `Default SELECT` afin de définir explicitement quelles colonnes sont renvoyées dans la vue des logs. Si des champs supplémentaires sont disponibles, comme le nom du service, le niveau de log ou une colonne body, ils peuvent aussi être configurés. La colonne d’affichage de l’horodatage peut également être redéfinie si elle diffère de la colonne utilisée dans la clé primaire de la table et configurée ci-dessus.
Dans l’exemple ci-dessus, il n’existe pas de colonne `Body` dans les données. À la place, elle est définie à l’aide d’une expression SQL qui reconstitue une ligne de log Nginx à partir des champs disponibles.
Pour connaître les autres options possibles, consultez la [référence de configuration](/fr/clickstack/managing/config).
Une fois la source créée, vous devriez être redirigé vers la vue de recherche, où vous pourrez immédiatement commencer à explorer vos données.
Cette configuration suppose un schéma de type Nginx avec une colonne `time_local` utilisée comme horodatage. Idéalement, il doit s’agir de la colonne d’horodatage déclarée dans la clé primaire. **Cette colonne est obligatoire**.
Nous vous recommandons également de mettre à jour `Default SELECT` afin de définir explicitement quelles colonnes sont renvoyées dans la vue des logs. Si des champs supplémentaires sont disponibles, comme le nom du service, le niveau de log ou une colonne body, ils peuvent aussi être configurés. La colonne d’affichage de l’horodatage peut également être redéfinie si elle diffère de la colonne utilisée dans la clé primaire de la table et configurée ci-dessus.
Dans l’exemple ci-dessus, il n’existe pas de colonne `Body` dans les données. À la place, elle est définie à l’aide d’une expression SQL qui reconstitue une ligne de log Nginx à partir des champs disponibles.
Pour connaître les autres options possibles, consultez la [référence de configuration](/fr/clickstack/managing/config).
Une fois la source créée, vous devriez être redirigé vers la vue de recherche, où vous pourrez immédiatement commencer à explorer vos données.
Et c’est tout — vous êtes prêt. 🎉
Vous pouvez maintenant explorer ClickStack : commencez à rechercher dans les logs et les traces, observez comment les logs, les traces et les métriques se corrèlent en temps réel, créez des tableaux de bord, explorez les Service maps, découvrez Event deltas et Patterns, et configurez des alertes pour garder une longueur d’avance sur les problèmes.
### Sélectionner un service
Depuis la page d’accueil de ClickHouse Cloud, sélectionnez le service pour lequel vous souhaitez activer Managed ClickStack.
**Estimation des ressources**
Ce guide suppose que vous avez provisionné suffisamment de ressources pour prendre en charge le volume de données d’observability que vous prévoyez d’ingérer et d’interroger avec ClickStack. Pour estimer les ressources nécessaires, consultez le guide [Estimating Resources](/fr/clickstack/managing/estimating-resources).
Si votre service ClickHouse héberge déjà d’autres charges de travail, comme de l’analytics applicatif en temps réel, nous vous recommandons de créer un service enfant à l’aide de la [fonctionnalité warehouses de ClickHouse Cloud](/fr/products/cloud/features/infrastructure/warehouses) afin d’isoler la charge de travail d’observability. Cela garantit que vos applications existantes ne seront pas perturbées, tout en gardant les jeux de données accessibles depuis les deux services.
### Accédez à la ClickStack UI
Sélectionnez 'ClickStack' dans le menu de navigation de gauche. Vous serez redirigé vers la ClickStack UI et authentifié automatiquement selon vos permissions ClickHouse Cloud.
Si des tables OpenTelemetry existent déjà dans votre service, elles seront détectées automatiquement et les sources de données correspondantes seront créées.
**Détection automatique des sources de données**
La détection automatique s’appuie sur le schéma de table OpenTelemetry standard fourni par la distribution ClickStack du collector OpenTelemetry. Des sources sont créées pour la base de données qui dispose de l’ensemble de tables le plus complet. Des tables supplémentaires peuvent être ajoutées comme [sources de données distinctes](/fr/clickstack/managing/config#datasource-settings) si nécessaire.
Si la détection automatique réussit, vous devriez être redirigé vers la vue de recherche, où vous pourrez immédiatement commencer à explorer vos données.
Si cette étape réussit, c’est terminé : tout est prêt 🎉. Sinon, passez à la configuration de l’ingestion.
### Configurer l'ingestion
Si la détection automatique échoue ou si vous n'avez aucune table existante, vous serez invité à configurer l'ingestion.
Sélectionnez "Start Ingestion" et vous serez invité à choisir une source d'ingestion. Managed ClickStack prend en charge OpenTelemetry et [Vector](https://vector.dev/) comme principales sources d'ingestion. Les utilisateurs sont également libres d'envoyer des données directement à ClickHouse dans leur propre schéma en utilisant l'une des [intégrations compatibles avec ClickHouse Cloud](/fr/integrations/home).
**OpenTelemetry recommandé**
L’utilisation d’OpenTelemetry comme format d’ingestion est fortement recommandée.
Il offre la solution la plus simple et la plus optimisée, avec des schémas prêts à l’emploi spécialement conçus pour fonctionner efficacement avec ClickStack.
Pour envoyer des données OpenTelemetry à Managed ClickStack, il est recommandé d’utiliser un OpenTelemetry Collector. Le collecteur agit comme une passerelle : il reçoit les données OpenTelemetry de vos applications (et d’autres collecteurs) et les transmet à ClickHouse Cloud.
Si vous n’en avez pas déjà un en cours d’exécution, démarrez un collecteur en suivant les étapes ci-dessous. Si vous avez déjà des collecteurs en place, un exemple de configuration est également fourni.
### Démarrer un collecteur
La procédure ci-dessous suit l’approche recommandée, qui consiste à utiliser la **distribution ClickStack de l’OpenTelemetry Collector**, laquelle inclut un traitement supplémentaire et est optimisée spécifiquement pour ClickHouse Cloud. Si vous souhaitez utiliser votre propre OpenTelemetry Collector, consultez ["Configurer des collecteurs existants."](#configure-existing-collectors)
Pour démarrer rapidement, copiez et exécutez la commande Docker affichée.
**Modifiez cette commande avec les identifiants de votre service, enregistrés lors de la création de celui-ci.**
**Déploiement en production**
Bien que cette commande utilise l’utilisateur `default` pour se connecter à Managed ClickStack, vous devez créer un utilisateur dédié lors du [passage en production](/fr/clickstack/managing/production#create-a-database-ingestion-user-managed) et modifier votre configuration.
L’exécution de cette seule commande démarre le collecteur ClickStack avec des endpoints OTLP exposés sur les ports 4317 (gRPC) et 4318 (HTTP). Si vous disposez déjà d’une instrumentation OpenTelemetry et d’agents, vous pouvez immédiatement commencer à envoyer des données de télémétrie vers ces endpoints.
### Configurer des collecteurs existants
Vous pouvez également configurer vos propres OpenTelemetry Collectors existants ou utiliser votre propre distribution du collector.
**ClickHouse exporter requis**
Si vous utilisez votre propre distribution, par exemple l’[image contrib](https://github.com/open-telemetry/opentelemetry-collector-contrib), assurez-vous qu’elle inclut le [ClickHouse exporter](https://github.com/open-telemetry/opentelemetry-collector-contrib/tree/main/exporter/clickhouseexporter).
À cet effet, un exemple de configuration OpenTelemetry Collector est fourni. Il utilise le ClickHouse exporter avec les paramètres appropriés et expose des receivers OTLP. Cette configuration correspond aux interfaces et au comportement attendus par la distribution ClickStack.
Un exemple de cette configuration est présenté ci-dessous (les variables d'environnement seront préremplies si vous copiez depuis l'UI) :
```yaml theme={null}
receivers:
otlp/hyperdx:
protocols:
grpc:
include_metadata: true
endpoint: "0.0.0.0:4317"
http:
cors:
allowed_origins: ["*"]
allowed_headers: ["*"]
include_metadata: true
endpoint: "0.0.0.0:4318"
processors:
batch:
memory_limiter:
# 80% of maximum memory up to 2G, adjust for low memory environments
limit_mib: 1500
# 25% of limit up to 2G, adjust for low memory environments
spike_limit_mib: 512
check_interval: 5s
connectors:
routing/logs:
default_pipelines: [logs/out-default]
error_mode: ignore
table:
- context: log
statement: route() where IsMatch(attributes["rr-web.event"], ".*")
pipelines: [logs/out-rrweb]
exporters:
debug:
verbosity: detailed
sampling_initial: 5
sampling_thereafter: 200
clickhouse/rrweb:
database: default
endpoint:
password:
username: default
ttl: 720h
logs_table_name: hyperdx_sessions
timeout: 5s
retry_on_failure:
enabled: true
initial_interval: 5s
max_interval: 30s
max_elapsed_time: 300s
clickhouse:
database: default
endpoint:
password:
username: default
ttl: 720h
timeout: 5s
retry_on_failure:
enabled: true
initial_interval: 5s
max_interval: 30s
max_elapsed_time: 300s
service:
pipelines:
traces:
receivers: [otlp/hyperdx]
processors: [memory_limiter, batch]
exporters: [clickhouse]
metrics:
receivers: [otlp/hyperdx]
processors: [memory_limiter, batch]
exporters: [clickhouse]
logs/in:
receivers: [otlp/hyperdx]
exporters: [routing/logs]
logs/out-default:
receivers: [routing/logs]
processors: [memory_limiter, batch]
exporters: [clickhouse]
logs/out-rrweb:
receivers: [routing/logs]
processors: [memory_limiter, batch]
exporters: [clickhouse/rrweb]
```
Pour plus de détails sur la configuration des collecteurs OpenTelemetry, consultez ["Ingestion avec OpenTelemetry."](/fr/clickstack/ingesting-data/opentelemetry)
### Démarrer l’ingestion (facultatif)
Si vous avez déjà des applications ou une infrastructure à instrumenter avec OpenTelemetry, consultez les guides pertinents accessibles depuis "Connecter une application".
Pour instrumenter vos applications afin de collecter des traces et des logs, utilisez les [SDKs de langage pris en charge](/fr/clickstack/ingesting-data/sdks/index), qui envoient les données à votre OpenTelemetry Collector, lequel agit comme une passerelle pour l’ingestion dans Managed ClickStack.
Les logs peuvent être [collectés à l’aide d’OpenTelemetry Collectors](/fr/clickstack/integration-examples/host-logs) exécutés en mode agent et transmis au même collecteur. Pour le monitoring Kubernetes, suivez le [guide dédié](/fr/clickstack/integration-examples/kubernetes). Pour les autres intégrations, consultez nos [guides de démarrage rapide](/fr/clickstack/integration-examples/index).
[Vector](https://vector.dev) est un pipeline de données d’observabilité haute performance, indépendant des fournisseurs, particulièrement apprécié pour l’ingestion de logs grâce à sa flexibilité et à sa faible empreinte sur les ressources.
Lorsque vous utilisez Vector avec ClickStack, vous devez définir vos propres schémas. Ces schémas peuvent suivre les conventions OpenTelemetry, mais ils peuvent aussi être entièrement personnalisés et représenter des structures d’événements définies par l’utilisateur.
**Horodatage requis**
La seule exigence stricte pour Managed ClickStack est que les données incluent une **colonne d’horodatage** (ou un champ temporel équivalent), qui peut être déclarée lors de la configuration de la source de données dans la ClickStack UI.
La suite suppose qu’une instance de Vector est en cours d’exécution, préconfigurée avec des pipelines d’ingestion et qu’elle achemine les données.
### Créer une base de données et une table
Vector exige qu’une table et un schéma soient définis avant l’ingestion des données.
Commencez par créer une base de données. Vous pouvez le faire via la [ClickHouse Cloud console](/fr/products/cloud/features/sql-console-features/sql-console).
Par exemple, créez une base de données pour les logs :
```sql theme={null}
CREATE DATABASE IF NOT EXISTS logs
```
Créez ensuite une table dont le schéma correspond à la structure de vos données de logs. L’exemple ci-dessous se base sur un format classique de journal d’accès Nginx :
```sql theme={null}
CREATE TABLE logs.nginx_logs
(
`time_local` DateTime,
`remote_addr` IPv4,
`remote_user` LowCardinality(String),
`request` String,
`status` UInt16,
`body_bytes_sent` UInt64,
`http_referer` String,
`http_user_agent` String,
`http_x_forwarded_for` LowCardinality(String),
`request_time` Float32,
`upstream_response_time` Float32,
`http_host` String
)
ENGINE = MergeTree
ORDER BY (toStartOfMinute(time_local), status, remote_addr);
```
Votre table doit correspondre au schéma de sortie généré par Vector. Ajustez le schéma en fonction de vos données, en suivant les [bonnes pratiques recommandées pour les schémas](/fr/concepts/best-practices/select-data-type).
Nous vous recommandons vivement de bien comprendre le fonctionnement des [clés primaires](/fr/concepts/core-concepts/primary-indexes) dans ClickHouse et de choisir une clé de tri en fonction de vos modes d’accès. Consultez les recommandations [spécifiques à ClickStack](/fr/clickstack/managing/performance-tuning#choosing-a-primary-key) pour choisir une clé primaire.
Une fois la table créée, copiez l’extrait de configuration affiché. Ajustez l’entrée pour utiliser vos pipelines existants, ainsi que la table cible et la base de données si nécessaire. Les identifiants devraient déjà être préremplis.
Pour plus d’exemples d’ingestion de données avec Vector, consultez ["Ingestion avec Vector"](/fr/clickstack/ingesting-data/vector) ou la [documentation du sink ClickHouse de Vector](https://vector.dev/docs/reference/configuration/sinks/clickhouse/) pour accéder aux options avancées.
### Accédez à l’interface ClickStack
Une fois la configuration de l’ingestion terminée et l’envoi des données démarré, sélectionnez "Next".
Si vous avez ingéré des données OpenTelemetry à l’aide de ce guide, les sources de données sont créées automatiquement et aucune configuration supplémentaire n’est nécessaire. Vous pouvez commencer à explorer ClickStack immédiatement. Vous serez redirigé vers la vue Search avec une source automatiquement sélectionnée, afin de pouvoir commencer à interroger les données immédiatement.
C’est tout — tout est prêt 🎉.
Si vous avez ingéré des données via Vector ou une autre source, vous serez invité à configurer la source de données.
La configuration ci-dessus suppose un schéma de type Nginx avec une colonne `time_local` utilisée comme horodatage. Il doit s’agir, dans la mesure du possible, de la colonne d’horodatage déclarée dans la clé primaire. **Cette colonne est obligatoire**.
Nous vous recommandons également de mettre à jour `Default SELECT` pour définir explicitement les colonnes renvoyées dans la vue des logs. Si des champs supplémentaires sont disponibles, comme le nom du service, le niveau de log ou une colonne body, ils peuvent également être configurés. La colonne d’affichage de l’horodatage peut aussi être remplacée si elle diffère de celle utilisée dans la clé primaire de la table et configurée ci-dessus.
Dans l’exemple ci-dessus, il n’existe pas de colonne `Body` dans les données. Elle est à la place définie à l’aide d’une expression SQL qui reconstitue une ligne de log Nginx à partir des champs disponibles.
Pour connaître les autres options possibles, consultez la [référence de configuration](/fr/clickstack/managing/config#hyperdx).
Une fois la source configurée, cliquez sur "Save" et commencez à explorer vos données.
## Tâches supplémentaires
### Accorder l’accès à Managed ClickStack
1. Accédez à votre service dans la console ClickHouse Cloud
2. Accédez à **Settings** → **SQL Console Access**
3. Définissez le niveau d’autorisation approprié pour chaque utilisateur :
* **Service Admin → Full Access** - Requis pour activer les alerts
* **Service Read Only → Read Only** - Permet de consulter les données d’observabilité et de créer des dashboards
* **No access** - Ne permet pas d’accéder à HyperDX
**Les alerts nécessitent des droits d’administrateur**
Pour activer les alerts, au moins un utilisateur disposant des permissions **Service Admin** (associées à **Full Access** dans la liste déroulante **SQL Console Access**) doit se connecter à HyperDX au moins une fois. Cela crée dans la base de données un utilisateur dédié qui exécute les requêtes d’alerts.
### Utiliser ClickStack avec des ressources de calcul en lecture seule
L'interface utilisateur de ClickStack peut fonctionner entièrement sur un service ClickHouse Cloud en lecture seule. Il s'agit de la configuration recommandée si vous souhaitez isoler les charges de travail d'ingestion et de requête.
#### Comment ClickStack sélectionne la ressource de calcul
L’interface utilisateur de ClickStack se connecte toujours au service ClickHouse depuis lequel il est lancé dans la ClickHouse Cloud Console.
Cela signifie :
* Si vous ouvrez ClickStack depuis un service en lecture seule, toutes les requêtes émises par l’interface utilisateur de ClickStack s’exécuteront sur cette ressource de calcul en lecture seule.
* Si vous ouvrez ClickStack depuis un service en lecture-écriture, ClickStack utilisera cette ressource de calcul à la place.
Aucune configuration supplémentaire dans ClickStack n’est nécessaire pour garantir le mode lecture seule.
#### Configuration recommandée
Pour exécuter ClickStack sur des ressources de calcul en lecture seule :
1. Créez ou repérez un service ClickHouse Cloud dans le warehouse configuré en lecture seule.
2. Dans la console ClickHouse Cloud, sélectionnez le service en lecture seule.
3. Lancez ClickStack depuis le menu de navigation de gauche.
Une fois lancé, ClickStack UI s’associera automatiquement à ce service en lecture seule.
### Ajouter d’autres sources de données
ClickStack est nativement compatible avec OpenTelemetry, sans lui être exclusif : vous pouvez utiliser vos propres schémas de table si vous le souhaitez.
La section suivante explique comment ajouter des sources de données supplémentaires en plus de celles configurées automatiquement.
#### Utiliser les schémas OpenTelemetry
Si vous utilisez un OTel collector pour créer la base de données et les tables dans ClickHouse, conservez toutes les valeurs par défaut dans le formulaire de création de source et renseignez le champ `Table` avec la valeur `otel_logs` afin de créer une source de logs. Tous les autres paramètres devraient être détectés automatiquement, ce qui vous permettra de cliquer sur `Enregistrer la nouvelle source`.
Pour créer des sources pour les traces et les métriques OTel, vous pouvez sélectionner `Créer une nouvelle source` dans le menu supérieur.
Sélectionnez ensuite le type de source requis, puis la table appropriée ; par exemple, pour les traces, sélectionnez la table `otel_traces`. Tous les paramètres devraient être détectés automatiquement.
**Sources corrélées**
Notez que différentes sources de données dans ClickStack — comme les logs et les traces — peuvent être corrélées entre elles. Pour activer cette fonctionnalité, une configuration supplémentaire est nécessaire pour chaque source. Par exemple, dans la source de logs, vous pouvez spécifier une source de traces correspondante, et inversement dans la source de traces. Voir [« Sources corrélées »](/fr/clickstack/managing/config#correlated-sources) pour plus de détails.
#### Utiliser des schémas personnalisés
Les utilisateurs qui souhaitent connecter ClickStack à un service existant contenant déjà des données peuvent renseigner les paramètres de base de données et de table nécessaires. Les paramètres seront détectés automatiquement si les tables respectent les schémas OpenTelemetry pour ClickHouse.
Si vous utilisez votre propre schéma, nous vous recommandons de créer une source de logs en veillant à ce que les champs requis soient bien définis ; voir ["Paramètres de la source de logs"](/fr/clickstack/managing/config#logs) pour plus de détails.
## Choix du schéma : Map vs JSON
Par défaut, ClickStack stocke les attributs dans des colonnes `Map(LowCardinality(String), String)`. Il s’agit du schéma recommandé pour les charges de travail d’observabilité. Associé à la [sérialisation de map compartimentée](/fr/reference/data-types/map#bucketed-map-serialization) et à des index textuels sur les clés et les valeurs de la map, il permet des recherches sélectives sans la surcharge d’ingestion par clé propre aux sous-colonnes JSON dynamiques.
Un schéma de type `JSON` est disponible en bêta pour évaluation sur des charges de travail avec un ensemble réduit et stable de clés d’attributs. Il n’est **pas recommandé** par défaut. Consultez [Map vs JSON type](/fr/clickstack/ingesting-data/schema/map-vs-json) pour la comparaison complète et les variables d’environnement requises pour activer la prise en charge de JSON.